


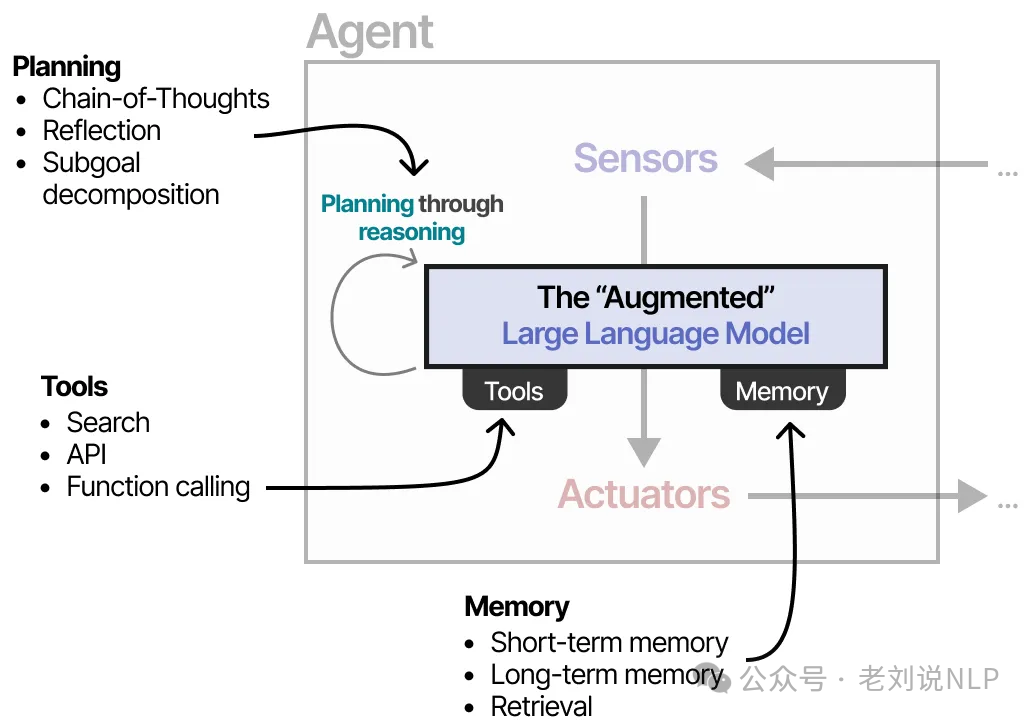

学习 Agent,越学越像在重新理解操作系统
引言
2024 年,当我第一次深入研究 Agent 框架时,产生了一个奇怪的感觉:这不就是重新发明操作系统吗?
进程、线程、系统调用、内存管理、文件系统、设备驱动……这些在大学操作系统课程里让我头疼不已的概念,在 Agent 世界里全都以另一种面貌出现了。只不过是换了层皮——从 CPU 和内存,变成了 Token 和推理时间。
花了半年时间,终于把这条暗线理清楚了。今天这篇文章,就是把我看到的、想到的、踩过的坑,全都记录下来。希望你读完之后,能和我有同样的感受:"原来如此!"
壹、从一个痛点说起
先问个问题:你有没有这种感觉——
学 Agent 的时候,总有一堆新概念要记:ReAct、CoT、ToV、Plan-and-Execute、MRKL、Harness、Orchestrator、Sub-Agent、Context Window、Function Calling……
学完一遍,脑子里全是碎片。
但有一天,我突然发现:这些概念我都见过。
不是在 AI 论文里,而是在操作系统教科书里。
进程隔离 = Agent 隔离
系统调用 = Tool Use / Function Calling
虚拟内存分页 = Context Compression
文件系统挂载 = RAG
进程调度器 = Orchestrator
信号量 / 锁 = Agent 之间的同步机制
操作系统花了几十年解决的问题,Agent 时代正在用同样的思路重新解决一遍。
这不是巧合。这是历史在押韵。
贰、进程与线程 → Sub-Agent
2.1 操作系统里的进程和线程
在操作系统里,进程(Process)是资源分配的基本单位,线程(Thread)是 CPU 调度的基本单位。
这意味着:
- 每个进程有自己独立的地址空间(内存)、文件句柄、系统资源
- 同一进程里的线程共享这些资源,但各自有独立的栈和寄存器
- 进程间通信(IPC)需要显式的机制:管道、消息队列、共享内存、Socket……
- 线程间通信相对简单,因为共享内存——但也带来了**竞争条件(Race Condition)**的风险
这段话看起来枯燥,但让我举个例子你就明白了。
场景:一个 Web 服务器(进程),处理多个请求(线程)。
进程(Web 服务器)
├── 线程1:处理用户A的请求
├── 线程2:处理用户B的请求
├── 线程3:处理用户C的请求
└── ...(更多线程)
│
├── 共享资源:数据库连接池、缓存
├── 独立资源:每个线程自己的栈、局部变量
└── 潜在问题:多个线程同时修改同一个变量?
这就是经典的并发问题。如果线程 1 和线程 2 同时往数据库写入,而数据库连接池只有 5 个连接——两个线程抢同一个连接,就会出问题。
2.2 Agent 世界里的进程和线程
把上面这个场景映射到 Agent 世界:
- 进程 ≈ 独立的 Agent 实例(或者一个 Agent 系统)
- 线程 ≈ Sub-Agent / Worker
# 操作系统视角
class Process:
def __init__(self):
self.memory = Memory() # 独立地址空间
self.files = FileHandles()
self.threads = []
# Agent 视角
class Agent:
def __init__(self, model, tools):
self.memory = Memory() # Agent 的"内存"
self.context = [] # Agent 的"上下文"
self.sub_agents = [] # Sub-Agent 们
当我们在设计多 Agent 系统时,几乎立刻遇到了和操作系统一样的问题:
问题 1:谁能访问谁的状态?
如果 Agent A 在处理用户查询,Agent B 在做代码执行,它们能共享同一个 Memory 吗?
- 共享 → 效率高,但有数据竞争风险
- 隔离 → 安全,但信息传递成本高
问题 2:共享上下文带来竞争条件
时间线:
T1: Agent A 读取 shared_memory["result"] = None
T2: Agent A 开始计算
T3: Agent B 读取 shared_memory["result"] = None (还是空的!)
T4: Agent A 计算完成,写入 shared_memory["result"] = "答案A"
T5: Agent B 计算完成,写入 shared_memory["result"] = "答案B" (覆盖了!)
这就是经典的 ABA 问题——Agent B 读到的是过期的数据。
问题 3:死锁
场景:
- Agent A 等 Agent B 的结果
- Agent B 等 Agent A 的结果
→ 系统卡死
这些问题,操作系统花了几十年才解决。Agent 时代正在用同样的思路重新应对。
2.3 解决方案:操作系统用过的那些招
方案一:消息传递(Message Passing)
操作系统中,进程之间通过消息队列通信,不共享内存:
# 操作系统:进程间消息传递
class MessageQueue:
def send(self, pid, message):
self.queue[pid].append(message)
def receive(self, pid):
return self.queue[pid].pop(0)
# Agent 世界:Agent 间消息传递
class AgentMessageBus:
def send(self, from_agent, to_agent, message):
self.queue[to_agent].append({
"from": from_agent,
"content": message,
"timestamp": time.time()
})
def receive(self, agent_id):
return self.queue[agent_id].pop(0)
方案二:Actor 模型
这是分布式系统里很经典的模型,和 Agent 设计高度吻合:
- 每个 Actor(Agent)有独立的"邮箱"
- Actor 之间不共享状态,通过消息通信
- 消息是异步的,有 mailbox 缓冲
Actor A ──消息──→ Actor B 的 Mailbox
↑ │
└──── 响应消息 ───────┘
方案三:锁和信号量
如果必须共享状态,就需要同步机制:
import asyncio
class SharedContext:
def __init__(self):
self._lock = asyncio.Lock()
self._data = {}
async def read(self, key):
async with self._lock:
return self._data.get(key)
async def write(self, key, value):
async with self._lock:
self._data[key] = value
这和操作系统的 ** 读写锁(Read-Write Lock)** 完全是一个思路。
2.4 实战经验
我曾经在做一个多 Agent 协作系统时踩过坑:
场景:一个 Researcher Agent 负责搜索信息,一个 Writer Agent 负责写文章,一个 Editor Agent 负责审核。
问题:三个 Agent 共享一个 research_notes 变量,Editor 在 Writer 还没写完时就读取了。
解决:参考操作系统的生产者 - 消费者模式,引入消息队列和状态机:
状态机:
WRITING → EDITING → APPROVED
↑
(等待 Writer 完成)
叁、系统调用 → Tool Use
3.1 操作系统里的系统调用
这是最经典、最核心的类比。
在操作系统里,用户程序不能直接访问硬件。你写的代码运行在 "用户态",硬件操作必须通过 "系统调用" 陷入 "内核态",由操作系统代为执行。
用户程序(用户态)
│
│ write() 系统调用
↓
内核(内核态)
│
│ 操作硬件
↓
磁盘 / 网卡 / 显示器
为什么要这样?安全。
如果任何程序都能直接写磁盘,那恶意软件可以随意破坏文件系统。
如果任何程序都能直接发网络包,那整个互联网都不安全。
系统调用就是在权限边界上打一个受控的洞:
- 能力从这个洞里流进来(程序可以读写文件、发送网络请求)
- 风险也从这个洞里被隔住(内核审核每个请求,确保安全)
典型的系统调用:
| 操作 | 系统调用 |
|---|---|
| 读文件 | read(fd, buffer, count) |
| 写文件 | write(fd, buffer, count) |
| 创建进程 | fork() / exec() |
| 分配内存 | mmap() / brk() |
| 网络通信 | socket() / connect() / send() |
| 访问设备 | ioctl() |
3.2 Agent 世界里的系统调用
Function Calling / Tool Use 就是 Agent 的系统调用。
Agent(LLM)本身不能搜索网页、不能执行代码、不能访问数据库。它只能 "推理"——根据输入生成输出。
要完成真实任务,必须通过 Function Calling 交给外部工具(Harness)执行:
Agent(LLM 推理)
│
│ Function Call: search_web("...")
↓
Harness(执行环境)
│
│ 执行工具
↓
搜索引擎 / 代码执行器 / 数据库
和操作系统一样,这也是一个权限边界:
- LLM 本身不知道也不需要知道工具怎么实现的
- Harness 负责审核、执行、返回结果
- 安全策略在 Harness 层控制(哪些工具可用?频率限制?)
3.3 详细对比
| 维度 | 操作系统 | Agent 系统 |
|---|---|---|
| 执行主体 | CPU | LLM |
| 调用方式 | syscall | Function Calling / Tool Use |
| 执行环境 | 内核态 | Harness |
| 权限控制 | 用户ID、Capabilities | API Key、权限配置 |
| 资源隔离 | 进程/容器 | 沙箱、API 限制 |
| 审计 | 系统日志 | 调用日志、成本追踪 |
3.4 Harness:Agent 的"内核"
在很多 Agent 框架里,Harness 是核心组件:
class Harness:
def __init__(self):
self.tools = {} # 注册的工具
self.policies = {} # 安全策略
self.resources = {} # 资源配额
async def execute(self, tool_call: ToolCall) -> ToolResult:
# 1. 权限检查
if not self._check_permission(tool_call):
raise PermissionError("Not authorized")
# 2. 资源配额检查
if not self._check_quota(tool_call):
raise ResourceExhaustedError("Quota exceeded")
# 3. 执行工具
tool = self.tools[tool_call.name]
result = await tool.execute(tool_call.args)
# 4. 审计日志
self._log(tool_call, result)
return result
这不就是操作系统的系统调用处理逻辑吗?
// 操作系统内核处理系统调用
asmlinkage long sys_write(unsigned int fd, const char __user *buf, size_t count) {
// 1. 权限检查(capable(CAP_SYS_WRITE)?)
if (!capable(CAP_SYS_WRITE))
return -EPERM;
// 2. 参数验证(buf 是否用户空间指针?)
if (!access_ok(buf, count))
return -EFAULT;
// 3. 执行业务逻辑
return vfs_write(fd, buf, count, &pos);
// 4. 审计
audit_syscall_entry(...);
}
3.5 工具定义的"ABI"
操作系统有 ABI(Application Binary Interface)——函数调用的二进制约定。
Function Calling 有类似的约定——工具的 schema:
{
"name": "search_web",
"description": "搜索互联网获取信息",
"parameters": {
"type": "object",
"properties": {
"query": {
"type": "string",
"description": "搜索关键词"
},
"max_results": {
"type": "integer",
"description": "最多返回结果数",
"default": 10
}
},
"required": ["query"]
}
}
这就是 Agent 的 "系统调用接口"。LLM 看到的工具定义,就像程序员看到的 man page。
肆、Cache / 虚拟内存 → Context Window
4.1 操作系统里的内存层级
计算机的内存系统是一个金字塔结构:
金字塔顶部(最快、最贵、最小)
━━━━━━━━━━━━━━━━━━━━━━
寄存器 (~1 KB) 纳秒级
━━━━━━━━━━━━━━━━━━━━━━
L1 Cache (~32 KB) 纳秒级
━━━━━━━━━━━━━━━━━━━━━━
L2 Cache (~256 KB) 纳秒级
━━━━━━━━━━━━━━━━━━━━━━
L3 Cache (~8 MB) 十纳秒级
━━━━━━━━━━━━━━━━━━━━━━
内存 RAM (~16 GB) 百纳秒级
━━━━━━━━━━━━━━━━━━━━━━
SSD (~1 TB) 微秒级
━━━━━━━━━━━━━━━━━━━━━━
磁盘 (~10 TB) 毫秒级
━━━━━━━━━━━━━━━━━━━━━━
金字塔底部(最慢、最便宜、最大)
核心问题:资源是分层的,速度和容量永远矛盾。
解决方法:缓存和虚拟内存。
缓存(Cache):把常用数据放在快但小的存储里。
虚拟内存(Virtual Memory):把不常用的数据 "换出" 到慢但大的存储里。
# 操作系统内存管理
class MemoryManager:
def __init__(self, physical_memory, disk):
self.physical = physical_memory # 快速但有限
self.disk = disk # 慢速但海量
def access(self, addr):
if addr in TLB: # Translation Lookaside Buffer
return self.physical[addr] # 命中,快!
page = self.page_table[addr]
if not page.in_memory:
# 页面置换:把不常用的页换出到磁盘
victim = self.find_victim_page()
self.swap_out(victim)
self.swap_in(page)
return self.physical[addr]
4.2 Context Window:Agent 的"内存"
Context Window 就是 LLM 的 "工作内存"。
当前最强模型也就 200K token 左右(GPT-4o),而这对于处理复杂任务来说其实很有限。
类比映射:
| 操作系统 | Agent 世界 |
|---|---|
| 寄存器 | 当前正在处理的 token |
| L1/L2 Cache | 最近几轮对话 |
| RAM | 完整对话上下文 |
| 虚拟内存/交换区 | 压缩摘要、外部存储 |
| 页面置换算法 | Context Compression |
4.3 Context Compression:内存分页的 Agent 版
当 Context Window 快满的时候,必须做压缩或摘要:
class ContextManager:
def __init__(self, max_tokens=128000):
self.max_tokens = max_tokens
self.messages = []
self.summaries = {} # 压缩后的摘要
def add_message(self, role, content):
self.messages.append({"role": role, "content": content})
# 检查是否超出限制
current_tokens = self.count_tokens(self.messages)
if current_tokens > self.max_tokens * 0.8:
# 触发压缩
self._compress()
def _compress(self):
# 方法1:简单截断(丢弃最早的对话)
while self.count_tokens(self.messages) > self.max_tokens * 0.5:
self.messages.pop(0)
# 方法2:智能摘要(保留关键信息,压缩冗余)
# 用 LLM 本身生成摘要
old_content = self._get_old_messages()
summary = self.llm.summarize(f"请总结以下对话的要点:\n{old_content}")
self.summaries["phase_1"] = summary
# 方法3:分层记忆(工作记忆 vs 长期记忆)
working = self.messages[-10:] # 最近10轮
longterm = self.summaries # 历史摘要
这不就是操作系统的 "页面置换算法" 吗?
操作系统用 LRU、FIFO、Clock 算法决定哪些页面该换出。
Agent 用重要性、相关性、时效性决定哪些上下文该压缩。
4.4 分层记忆架构
借鉴操作系统的内存分层思想,可以设计 Agent 的分层记忆:
┌─────────────────────────────────────┐
│ 工作记忆(Working Memory) │ ~4K tokens
│ 当前任务、最近对话、临时变量 │
├─────────────────────────────────────┤
│ 短期记忆(Short-term Memory) │ ~32K tokens
│ 今天/本周的会话、活跃项目上下文 │
├─────────────────────────────────────┤
│ 长期记忆(Long-term Memory) │ 外部存储
│ 压缩摘要、用户偏好、历史经验 │
└─────────────────────────────────────┘
类比:
- 工作记忆 = CPU 寄存器 + L1 Cache
- 短期记忆 = RAM
- 长期记忆 = 虚拟内存/SSD
4.5 页面置换策略的 Agent 实践
操作系统有很多经典的页面置换算法:
| 算法 | 思想 | Agent 对应 |
|---|---|---|
| LRU | 置换最久未使用的 | 置换最早对话 |
| LFU | 置换使用频率最低的 | 置换最少提及的概念 |
| FIFO | 置换最早的 | 置换时间最早的 |
| Working Set | 保留活跃页面 | 保留相关上下文 |
实践中的陷阱:
- 热恋期问题:Agent 在新对话开始时总是把所有历史都加载,导致 Context 膨胀
- 遗忘灾难:过度压缩导致关键信息丢失
- 语义碎片化:简单截断可能破坏语义完整性(比如截断到一句话中间)
伍、文件系统挂载 → RAG
5.1 操作系统里的文件系统
文件系统是操作系统最伟大的发明之一。
它把物理存储设备(磁盘、SSD、U 盘、网络存储)抽象成统一的文件树:
/ (根目录)
├── home/
│ └── user/
│ ├── documents/
│ │ ├── report.pdf
│ │ └── notes.txt
│ └── pictures/
│ └── photo.jpg
├── etc/
│ └── config.conf
└── tmp/
└── cache.dat
核心概念:挂载(Mount)
可以把任何存储设备挂载到文件树的任意位置:
# 把 U 盘挂载到 /mnt/usb
mount /dev/sdb1 /mnt/usb
# 把网络存储挂载到 /home/user/cloud
mount -t nfs 192.168.1.100:/share /home/user/cloud
# 把 ISO 镜像挂载到 /mnt/iso
mount -o loop image.iso /mnt/iso
按需加载:文件不用时不占内存,访问时才从磁盘读取。
用完释放:操作系统会在内存紧张时释放不常用的文件缓存。
5.2 RAG:Agent 的"文件系统挂载"
RAG(Retrieval-Augmented Generation) 就是把外部知识库 "挂载" 到 Agent 的上下文中。
┌─────────────────────────────────────────────┐
│ Agent 的"文件系统树" │
├─────────────────────────────────────────────┤
│ /context ← 当前对话 │
│ /memory ← 压缩记忆 │
│ /knowledge ← RAG 挂载点 │
│ │ ├── /company-docs ← 公司文档 │
│ │ ├── /product-manual ← 产品手册 │
│ │ └── /web-search-cache ← 搜索缓存 │
│ /tools ← 可用工具 │
└─────────────────────────────────────────────┘
5.3 RAG 的工作原理
class RAGSystem:
def __init__(self, vector_store, embedding_model):
self.store = vector_store # 向量数据库
self.embed = embedding_model
def retrieve(self, query: str, top_k: int = 5) -> List[Document]:
# 1. 把查询向量化
query_embedding = self.embed.encode(query)
# 2. 在向量数据库中搜索相似文档
results = self.store.similarity_search(
query_embedding,
top_k=top_k
)
return results
def mount_to_context(self, query: str) -> str:
# 1. 检索相关文档
docs = self.retrieve(query)
# 2. 组装成上下文
context = "\n\n".join([doc.content for doc in docs])
# 3. 添加到 prompt
return f"参考信息:\n{context}\n\n用户问题:{query}"
5.4 类比总结
| 操作系统 | Agent 系统 |
|---|---|
| 磁盘/SSD | 向量数据库(Milvus、Pinecone、Chroma) |
| 文件系统 | RAG 检索层 |
| mount 命令 | RAG 配置 / 知识库注册 |
| 文件 I/O | 向量相似度搜索 |
| 文件缓存 | 检索结果缓存 |
| 磁盘配额 | Token 预算控制 |
5.5 进阶:多层存储架构
和操作系统一样,可以设计多层 RAG 存储:
┌─────────────────────────────────────────┐
│ 热数据(Hot Storage) │ 实时检索
│ 常用文档、高频访问内容 │
├─────────────────────────────────────────┤
│ 温数据(Warm Storage) │ 定期同步
│ 近期文档、项目资料 │
├─────────────────────────────────────────┤
│ 冷数据(Cold Storage) │ 按需加载
│ 历史归档、罕见参考资料 │
└─────────────────────────────────────────┘
陆、内核 / 调度器 → Harness / Orchestrator
6.1 操作系统的内核
操作系统的内核(Kernel) 是整个系统的核心:
- 资源管理:CPU 时间片分配、内存分配、文件句柄、设备访问
- 权限控制:用户态/内核态切换、Capabilities、系统调用过滤
- 进程调度:决定哪个进程在哪个时刻运行
- 进程通信:信号、管道、消息队列、共享内存
调度器(Scheduler) 是内核最复杂的组件之一:
# 简化的调度器逻辑
class Scheduler:
def __init__(self):
self.ready_queue = [] # 就绪队列
self.running = None # 当前运行进程
def schedule(self):
# 1. 把已完成的进程移出
if self.running and self.running.is_terminated():
self.running = None
# 2. 把等待 I/O 的进程放回就绪队列
for proc in self.waiting:
if proc.is_io_complete():
self.ready_queue.append(proc)
# 3. 选择下一个进程运行
if not self.running and self.ready_queue:
self.running = self.ready_queue.pop(0)
self.running.state = RUNNING
# 4. 时间片用完,放回队列
if self.running and self.running.used_full_timeslice():
self.ready_queue.append(self.running)
self.running.state = READY
self.running = None
6.2 Harness:Agent 的"内核"
在 Agent 架构里,Harness 扮演着类似内核的角色:
class Harness:
def __init__(self, llm, tools, memory):
self.llm = llm # LLM = "CPU"
self.tools = tools # 工具 = "系统调用"
self.memory = memory # 记忆 = "内存"
self.state = {} # Agent 状态
self.quota = Quota() # 资源配额
async def execute(self, task: str) -> str:
# 1. 准备上下文
context = await self._prepare_context(task)
# 2. LLM 推理(可能多次)
while not self._is_complete():
# LLM 生成下一步
action = await self.llm.think(context)
# 如果是系统调用,执行工具
if action.is_tool_call():
result = await self._execute_tool(action)
context.add_result(result)
else:
# 直接输出
return action.content
return context.final_answer()
async def _execute_tool(self, tool_call: ToolCall):
# 权限检查
if not self._check_permission(tool_call):
raise PermissionDenied()
# 资源检查
if not self.quota.can_use(tool_call):
raise QuotaExceeded()
# 执行
tool = self.tools[tool_call.name]
return await tool.execute(tool_call.args)
6.3 Orchestrator:多 Agent 的调度器
当多个 Agent 协作时,需要 Orchestrator(编排器)来协调:
class Orchestrator:
def __init__(self, agents: List[Agent], task_graph: Dict):
self.agents = agents
self.task_graph = task_graph # 任务依赖关系
self.results = {}
async def run(self, root_task: str) -> Any:
# 1. 构建执行计划(类似拓扑排序)
execution_order = self._topological_sort(root_task)
# 2. 按顺序执行,支持并行
executed = set()
while executed != set(execution_order):
# 找出所有可以执行的 Agent(依赖已满足)
ready = [
agent for agent in self.agents
if agent.name in execution_order
and agent.name not in executed
and all(
dep in executed
for dep in self._get_dependencies(agent)
)
]
# 并行执行所有就绪的 Agent
if ready:
results = await asyncio.gather(*[
agent.execute(self.results) for agent in ready
])
for agent, result in zip(ready, results):
self.results[agent.name] = result
executed.add(agent.name)
else:
# 死锁检测
raise DeadlockError("No agents can proceed")
return self.results[root_task]
这和操作系统的进程调度完全是一个套路:
- 分析任务依赖(构建 DAG)
- 拓扑排序得到执行顺序
- 并行执行无依赖的任务
- 收集结果,继续下一批
- 检测死锁(环形依赖)
6.4 调度策略
操作系统有多种调度策略,Agent 系统也可以借鉴:
| 调度策略 | OS 场景 | Agent 应用 |
|---|---|---|
| FCFS | 简单批处理 | 顺序执行任务 |
| SJF | 最短任务优先 | 优先执行简单的 Agent |
| Round Robin | 时间片轮转 | 多 Agent 轮流执行 |
| 优先级调度 | 重要任务优先 | 关键 Agent 优先执行 |
| 多级反馈队列 | 兼顾响应和效率 | 简单任务快速通道,复杂任务深度处理 |
柒、安全模型:Capabilities vs 权限
7.1 操作系统的权限模型
操作系统用 Capabilities 或 ACL(访问控制列表) 来控制权限:
// Capabilities 模型
struct process {
cap_t cap; // 进程的能力集
};
// 检查是否有写文件权限
if (!cap_raised(proc->cap, CAP_DAC_OVERRIDE)) {
return -EACCES;
}
用户程序只能做它被授权的事情。
7.2 Agent 的权限模型
class ToolPermissions:
def __init__(self):
self.allowed_tools = set()
self.rate_limits = {}
self.data_scope = {} # 数据访问范围
def grant(self, tool: str, quota: dict):
self.allowed_tools.add(tool)
self.rate_limits[tool] = quota
def check(self, agent: str, tool: str) -> bool:
return tool in self.allowed_tools
# 使用示例
permissions = ToolPermissions()
permissions.grant("web_search", {"per_minute": 10, "per_day": 100})
permissions.grant("code_execution", {"per_hour": 50})
permissions.grant("read_files", {"/data/public/*": True, "/data/private/*": False})
捌、信号与中断 → 事件与回调
8.1 操作系统的中断机制
操作系统有中断机制来处理异步事件:
- 硬件中断:键盘输入、网卡数据包、磁盘 I/O 完成
- 软件中断:系统调用、异常、信号
// 信号处理
signal(SIGINT, handle_interrupt); // 注册 Ctrl+C 处理函数
void handle_interrupt(int sig) {
// 清理资源
cleanup();
exit(0);
}
8.2 Agent 的事件驱动
class AgentEventSystem:
def __init__(self):
self.handlers = {}
self.event_queue = asyncio.Queue()
def on(self, event: str, handler: Callable):
self.handlers[event] = handler
async def emit(self, event: str, data: Any):
await self.event_queue.put({"event": event, "data": data})
async def process_events(self):
while True:
event = await self.event_queue.get()
handler = self.handlers.get(event["event"])
if handler:
await handler(event["data"])
# 使用示例
events = AgentEventSystem()
events.on("tool_result", on_tool_result)
events.on("context_full", on_context_full)
events.on("agent_error", on_agent_error)
玖、调试与日志:/proc 文件系统 vs Agent 观测性
9.1 /proc:窥探系统状态
Linux 的 /proc 文件系统让用户可以查看内核状态:
cat /proc/1234/maps # 查看进程内存映射
cat /proc/1234/status # 查看进程状态
cat /proc/cpuinfo # CPU 信息
cat /proc/meminfo # 内存信息
9.2 Agent 的观测性
class AgentObserver:
def __init__(self):
self.metrics = {}
def log(self, event: AgentEvent):
self.metrics[event.type] = self.metrics.get(event.type, 0) + 1
def get_state(self, agent_id: str) -> dict:
return {
"agent_id": agent_id,
"current_task": self.get_current_task(agent_id),
"context_tokens": self.count_tokens(agent_id),
"tools_used": self.get_tools_used(agent_id),
"execution_time": self.get_elapsed_time(agent_id),
"errors": self.get_errors(agent_id)
}
def dump_trace(self, agent_id: str) -> str:
# 返回完整的执行轨迹,用于调试
return json.dumps(self.trace[agent_id], indent=2)
拾、容器与命名空间 → Agent 隔离
10.1 容器技术
Docker 和 Kubernetes 重新定义了 "进程隔离":
- PID Namespace:容器内的进程 ID 从 1 开始
- Network Namespace:容器有独立的网络栈
- Mount Namespace:容器有独立的文件系统视图
- User Namespace:容器内的用户 ID 可以映射到主机不同位置
# Docker 的隔离
docker run --pid=host nginx # 共享 PID 命名空间
docker run --network=host nginx # 共享网络命名空间
docker run -v /host/path:/container/path nginx # 共享挂载
10.2 Agent 隔离
类似地,Agent 系统也可以有不同级别的隔离:
class AgentSandbox:
def __init__(self, isolation_level: str):
self.isolation = isolation_level
# 完全隔离:独立记忆和工具
FULL = "full"
# 共享工具,隔离记忆
SHARED_TOOLS = "shared_tools"
# 共享记忆,隔离工具
SHARED_MEMORY = "shared_memory"
# 完全共享(危险!)
NONE = "none"
拾壹、未来展望
11.1 Agent 操作系统?
我在想一个问题:会不会有一天,出现类似 "Agent OS" 的东西?
- 进程 = Agent
- 文件系统 = 去中心化的知识图谱
- 系统调用 = 标准化的 Tool Interface
- 调度器 = Orchestrator
- 安全沙箱 = Capability-based Access Control
这不是科幻。事实上,很多框架已经在朝这个方向走:
- LangGraph 的状态机
- AutoGPT 的任务分解
- CrewAI 的 Agent 协作
- Microsoft AutoGen 的会话编排
11.2 我们能从 OS 历史学到什么?
操作系统几十年沉淀下来的智慧:
- 分层抽象:不要让每个层知道太多上层细节
- 最小权限原则:只授予完成任务所需的最小权限
- fail-safe 设计:出错了要安全地失败,不要搞垮整个系统
- 可观测性:运行时能看见内部状态,出了问题才能排查
- 资源隔离:防止一个组件拖垮整个系统
这些问题,Agent 时代正在重新面对。
结语:历史不会重复,但会押韵
马克·吐温说:"历史不会重复,但会押韵。"
操作系统花了几十年,从裸机编程演进到现代多任务系统:
- 进程隔离解决了安全问题
- 虚拟内存解决了容量问题
- 文件系统解决了存储抽象问题
- 调度器解决了资源分配问题
Agent 时代正在用同样的方式重新走这条路:
- Agent 隔离解决协作问题
- Context Compression 解决容量问题
- RAG 解决知识抽象问题
- Orchestrator 解决任务分配问题
当你觉得某个 Agent 设计似曾相识——
不妨回到操作系统教科书里找答案。那里面藏着你需要的解。
如果你觉得这篇文章有帮助,欢迎分享给同样在学习 Agent 的朋友。
历史在押韵,我们都是见证者。
评论交流
欢迎留下你的想法